课程主页:http://cs231n.stanford.edu/

_______________________________________________________________________________________________________________________________________________________
-Parameter Updates


解决的方法:
*Momentum update

其实就是把x再加上mu*v(可以看作是下滑过程中的摩擦力),这里的mu指的是一个从0.5到0.99的常数,v初始化为0.

除了Vanilla update, Momentum update,Nesterov Momentum这三种SGD之外,类似的优化方式还有:windowgrad,Adagrad,Adadelta,RMSprop,Adam。
这个网站给出了前6个在MNIST上的比较曲线,总体上adadelta效果略胜一筹。(引自:机器学习日报)
*learning rate decay


*Second order optimization methods
最优化问题里还有一个非常有名的,它按照如下的方式进行迭代更新参数:![]()
这里的![]() Hf(x)是,是函数的二阶偏微分。而
Hf(x)是,是函数的二阶偏微分。而![]() ∇f(x)和梯度下降里看到的一样,是一个梯度向量。直观理解是Hessian矩阵描绘出了损失函数的曲度,因此能让我们更高效地迭代和靠近最低点:乘以Hessian矩阵进行参数迭代会让在曲度较缓的地方,会用更激进的步长更新参数,而在曲度很陡的地方,步伐会放缓一些。因此相对一阶的更新算法,在这点上它还是有很足的优势的。
∇f(x)和梯度下降里看到的一样,是一个梯度向量。直观理解是Hessian矩阵描绘出了损失函数的曲度,因此能让我们更高效地迭代和靠近最低点:乘以Hessian矩阵进行参数迭代会让在曲度较缓的地方,会用更激进的步长更新参数,而在曲度很陡的地方,步伐会放缓一些。因此相对一阶的更新算法,在这点上它还是有很足的优势的。
比较尴尬的是,实际深度学习过程中,直接使用二次迭代的方法并不是很实用。原因是直接计算Hessian矩阵是一个非常耗时耗资源的过程。举个例子说,一个一百万参数的神经网络的Hessian矩阵维度为[1000000*1000000],算下来得占掉3725G的内存。当然,我们有这种近似Hessian矩阵的算法,可以解决内存问题。但是L-BFGS一般在全部数据集上计算,而不像我们用的mini-batch SGD一样在小batch小batch上迭代。现在有很多人在努力研究这个问题,试图让L-BFGS也能以mini-batch的方式稳定迭代更新。但就目前而言,大规模数据上的深度学习很少用到L-BFGS或者类似的二次迭代方法,倒是随机梯度下降这种简单的算法被广泛地使用着。
感兴趣的同学可以参考以下文献:
- :2011年的论文比较随机梯度下降和L-BFGS
- :google brain组的论文,比较随机梯度下降和L-BFGS在大规模分布式优化上的差别。
- 算法试图结合随机梯度下降和L-BFGS的优势。(引自:)
关于L-BFGS可以参考:

_______________________________________________________________________________________________________________________________________________________
-Evaluation: Model Ensembles



_______________________________________________________________________________________________________________________________________________________
-Regularization (dropout)防止过拟合
dropout
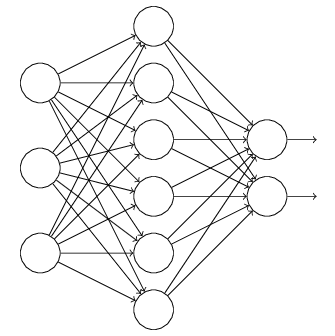
正则是通过在代价函数后面加上正则项来防止模型过拟合的。而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trike),对于如下所示的三层人工神经网络:
对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。
Dropout方法是通过修改ANN中隐藏层的神经元个数来防止ANN的过拟合(引自:)
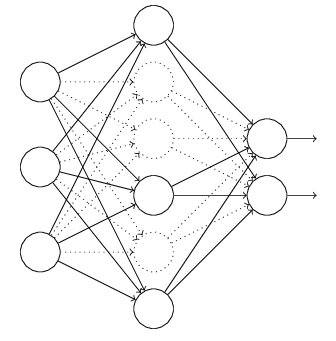

Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了(有点抽象,具体实现看后面的实验部分)。
按照hinton的文章,他使用Dropout时训练阶段和测试阶段做了如下操作:
在样本的训练阶段,在没有采用pre-training的网络时(Dropout当然可以结合pre-training一起使用),hintion并不是像通常那样对权值采用L2范数惩罚,而是对每个隐含节点的权值L2范数设置一个上限bound,当训练过程中如果该节点不满足bound约束,则用该bound值对权值进行一个规范化操作(即同时除以该L2范数值),说是这样可以让权值更新初始的时候有个大的学习率供衰减,并且可以搜索更多的权值空间(没理解)。
在模型的测试阶段,使用”mean network(均值网络)”来得到隐含层的输出,其实就是在网络前向传播到输出层前时隐含层节点的输出值都要减半(如果dropout的比例为50%),其理由文章说了一些,可以去查看(没理解)。
关于Dropout,文章中没有给出任何数学解释,Hintion的直观解释和理由如下:
1. 由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
2. 可以将dropout看作是模型平均的一种。对于每次输入到网络中的样本(可能是一个样本,也可能是一个batch的样本),其对应的网络结构都是不同的,但所有的这些不同的网络结构又同时share隐含节点的权值。这样不同的样本就对应不同的模型,是bagging的一种极端情况。个人感觉这个解释稍微靠谱些,和bagging,boosting理论有点像,但又不完全相同。
3. native bayes是dropout的一个特例。Native bayes有个错误的前提,即假设各个特征之间相互独立,这样在训练样本比较少的情况下,单独对每个特征进行学习,测试时将所有的特征都相乘,且在实际应用时效果还不错。而Droput每次不是训练一个特征,而是一部分隐含层特征。
4. 还有一个比较有意思的解释是,Dropout类似于性别在生物进化中的角色,物种为了使适应不断变化的环境,性别的出现有效的阻止了过拟合,即避免环境改变时物种可能面临的灭亡。(引自:)
